


1.ElasticSearch是什么
1.1ElasticSearch简介
Elasticsearch 是一个分布式、RESTful 风格的搜索和数据分析引擎
-
ElasticSearch特点:
- 分布式的文件存储,每个字段都被索引且可用于搜索。
- 分布式的实时分析搜索引擎,海量数据下近实时秒级响应。
- 简单的restful api,天生的兼容多语言开发。
- 易扩展,处理PB级结构化或非结构化数据
-
ElasticSearch缺点:
- 由于 Elasticsearch 需要处理大量的数据,因此需要较高的硬件性能和存储空间。
- 由于 Elasticsearch 是一个分布式系统,可能存在数据一致性问题
-
适用场景:
- 日志分析:Elasticsearch 可以快速地搜索和分析大量的日志数据。
- 搜索引擎:Elasticsearch 可以作为搜索引擎用于搜索和排序数据。
- 数据分析:Elasticsearch 可以用于数据分析,支持聚合和分析数据。
- 地理位置搜索:Elasticsearch 支持地理位置搜索,可以用于地图应用等。
1.2ES与Solr对比
- Solr是Apache Lucene项目的开源企业搜索平台。其主要功能包括全文检索、命中标示、分面搜索、动态聚类、数据库集成,以及富文本(如Word、PDF)的处理;Solr是高度可扩展的,并提供了分布式搜索和索引复制功能
- 当单纯的对已有数据进行搜索时,Solr更快;当实时建立索引时,Solr会产生io阻塞,查询性能较差
- 随着数据量的增加,Solr的搜索效率会变得更低,而Elasticsearch却没有明显的变化。
1.3ES与MySQL对比
- 结论:ElasticSearch比MySQL查询快,原因如下:
- 基于分词后的全文检索:
- 例如select * from test where name like ‘%张三%’,对于mysql来说,因为索引失效,会进行全表检索;
- 对es而言分词后,每个字都可以利用FST高速找到倒排索引的位置,并迅速获取文档id列表,大大的提升了性能,减少了磁盘IO
- 精确检索:
- 进行精确检索,有些时候可能mysql要快一些,当mysql的非聚合索引引用上了聚合索引,无需回表,则速度上可能更快;
- es还是通过FST找到倒排索引的位置比获取文档id列表,再根据文档id获取文档并根据相关度进行排序
- 但是es还有个优势,就是es即天然的分布式能够在大量数据搜索时可以通过分片降低检索规模,并且可以通过并行检索提升效率,用filter时,更是可以直接跳过检索直接走缓存
1.4ES基本概念

1.4.1Index-索引
Index,即索引,关键词有两种用法,可用作动词、或者名词
- 动词,相当于MySQL中的insert、插入
- 名词,相当于MySQL中的Database、数据库
1.4.2Type-类型
- 在Index(索引)中,可以定义一个或多个类型,每种类型的数据放一起;类似于MySQL中数据库中可以定义一个或多个表(Table);
- ES7、8版本差异:
- Elasticsearch 7. X URL中的type参数为可选。比如,索引一个文档不再要求提供文档类型。
- Elasticsearch 8.X 不再支持URL中的type参数。ElasticSearch8开始,将索引从多类型迁移到单类型,每种类型文档一个独立索引
- 原因:Elasticsearch是基于Lucene开发的搜索引擎,而==ES中不同type下名称相同的filed最终在Lucene中的处理方式是一样的==。不同type中的相同字段名称就会在处理中出现冲突的情况,导致Lucene处理效率下降,去掉type就是为了提高ES处理数据的效率。
1.4.3Document-文档
- 保存到某个索引(Index)下,某种类型(Type)的一个数据(Document),文档是JSON格式的
- 一个Document就像是MySQL中某个表的一条记录.
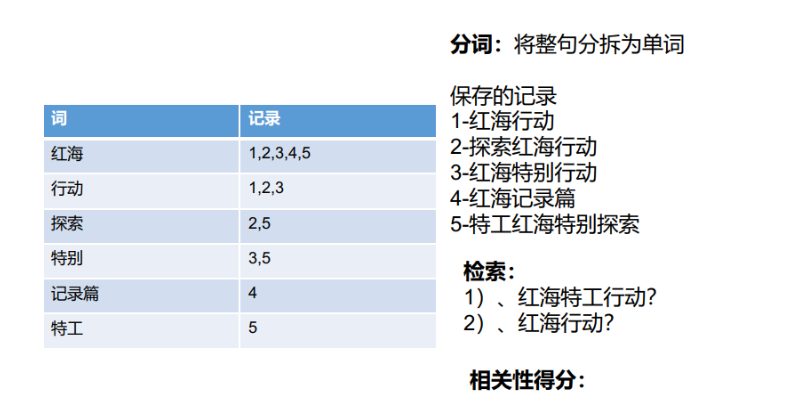
1.4.4倒排索引
由于不是由记录来确定属性值,而是由属性值来确定记录的位置,因而称为倒排索引(inverted index)
- 索引存储示例
将整句拆分为单词,将单词的值与索引存储起来,就可以根据单词查询索引位置,然后根据检索条件的相关性得分进行排序
2.安装ElasticSearch
2.1基于Docker安装ES与Kibana
2.1.1下载镜像文件
elasticsearch与kibana版本是同步的
docker pull elasticsearch:7.4.2 #存储和检索数据
docker pull kibana:7.4.2 #可视化检索数据
2.1.2创建实例
(1)创建ElasticSearch实例
#先将es的数据与配置与需要映射的文件夹创建好
mkdir -p /mydata/elasticsearch/config
mkdir -p /mydata/elasticsearch/data
#配置es地址
echo "http.host: 0.0.0.0" >> /mydata/elasticsearch/config/elasticsearch.yml
#保证权限
chmod -R 777 /mydata/elasticsearch/
#创建并启动实例
docker run --name elasticsearch -p 9200:9200 -p 9300:9300 \
-e "discovery.type=single-node" \-e ES_JAVA_OPTS="-Xms64m -Xmx512m" \
-v /mydata/elasticsearch/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml \
-v /mydata/elasticsearch/data:/usr/share/elasticsearch/data \
-v /mydata/elasticsearch/plugins:/usr/share/elasticsearch/plugins \
-d elasticsearch:7.4.2
-
注意:-e ES_JAVA_OPTS="-Xms64m -Xmx256m" \ 测试环境下, 设置 ES 的初始内存和最大内存, 否则会导致占用内存过多
-
效果:

-
ES的9200和9300端口区别
-
9200作为Http协议,主要用于外部通讯
-
9300作为Tcp协议,jar之间就是通过tcp协议通讯 .ES集群之间是通过9300进行通讯
-
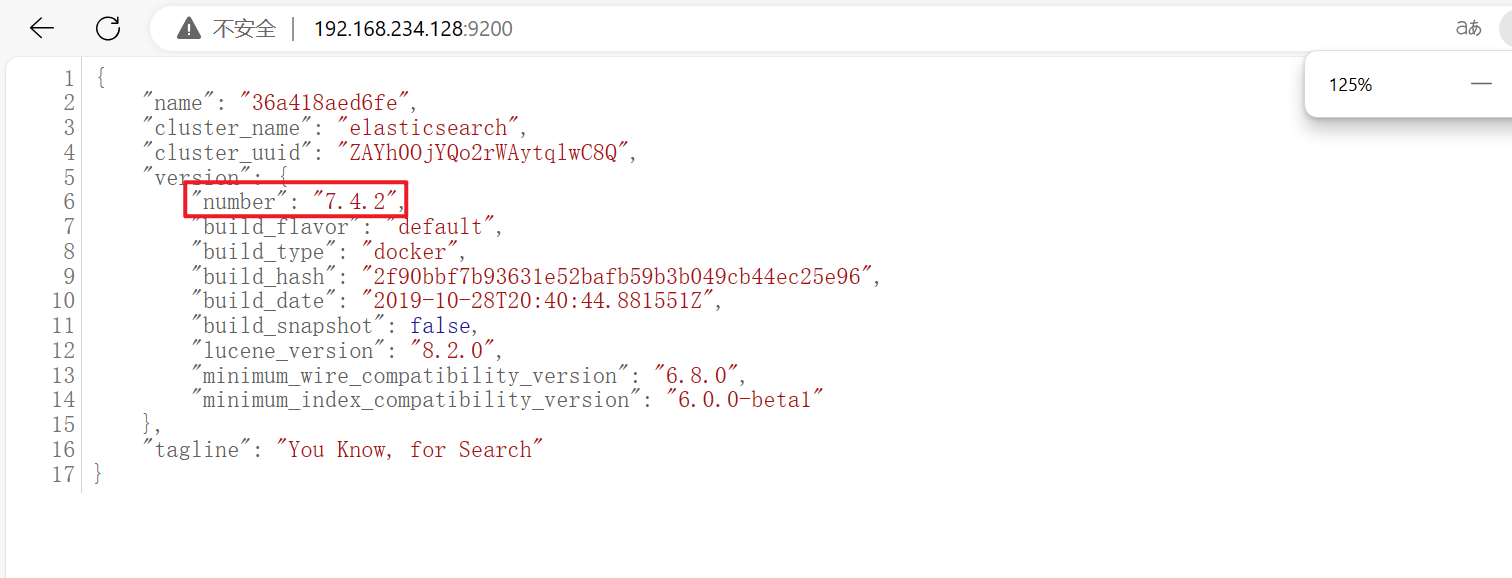
测试是否创建成功
192.168.234.128:9200 虚拟机地址+9200
记得防火墙开放9200端口
(2)创建Kibana实例
docker run --name kibana -e ELASTICSEARCH_HOSTS=http://192.168.234.128:9200 -p 5601:5601 \
-d kibana:7.4.2
测试是否创建成功
192.168.234.128:5601

2.1.3设置es和kibana自启动
先不设置,担心内存不够
# 设置es在docker开启的时候启动
docker update elasticsearch --restart=always
# 设置Kibana在docker开启的时候启动
docker update kibana --restart=always
2.2基于Windows安装ES与Kibana
待写


回复